fasttext 文本分类
Facebook FAIR实验室在2016年宣布将开源资料库fastText,声称相比深度模型,fastText能将训练时间由数天缩短到几秒钟。fastText简而言之的本质,就是把文档中所有词通过lookup table变成向量,取平均后直接用线性分类器得到分类结果。
1、简介
fastText是一种Facebook AI Research在16年开源的一个文本分类器。 其特点就是fast。相对于其它文本分类模型,如SVM,Logistic Regression和neural network等模型,fastText在保持分类效果的同时,大大缩短了训练时间。使用fastText进行文本分类的同时也会产生词的embedding,即embedding是fastText分类的产物。
word2vec把语料库中的每个单词当成原子的,它会为每个单词生成一个向量。这忽略了单词内部的形态特征,比如:“apple” 和“apples”,“达观数据”和“达观”,这两个例子中,两个单词都有较多公共字符,即它们的内部形态类似,但是在传统的word2vec中,这种单词内部形态信息因为它们被转换成不同的id丢失了。
为了克服这个问题,fastText使用了字符级别的n-grams来表示一个单词。对于单词“apple”,假设n的取值为3,则它的trigram有
“<ap”, “app”, “ppl”, “ple”, “le>”
其中,<表示前缀,>表示后缀。于是,我们可以用这些trigram来表示“apple”这个单词,进一步,我们可以用这5个trigram的向量叠加来表示“apple”的词向量。
这带来两点好处:
-
对于低频词生成的词向量效果会更好。因为它们的n-gram可以和其它词共享。
-
对于训练词库之外的单词,仍然可以构建它们的词向量。我们可以叠加它们的字符级n-gram向量。
2、CBOW和fasttext比较
CBOW模型的基本思路是:用上下文预测目标词汇。架构图如下所示:
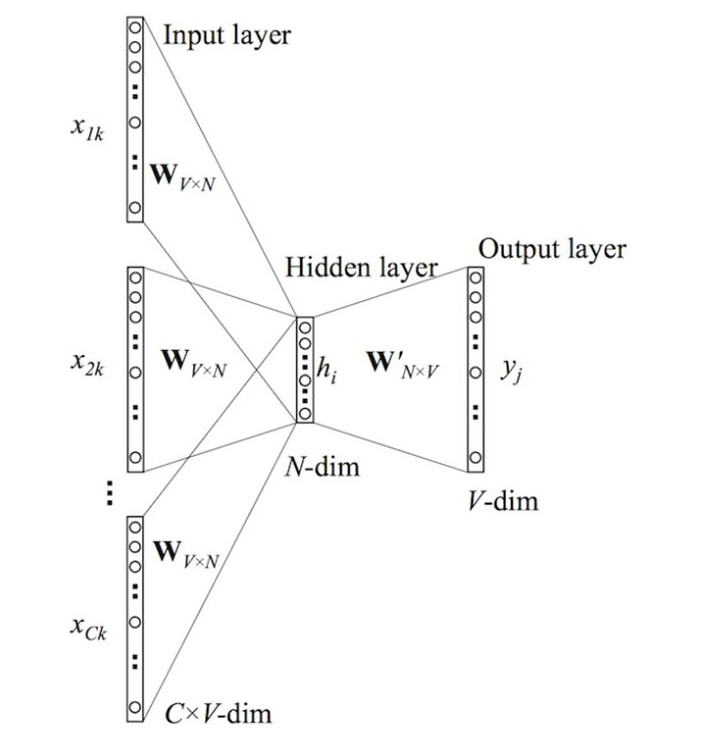
输入层由目标词汇y的上下文单词\({x_{1},...,x_{c}}\)组成,\(x_{i}\) 是被onehot编码过的V维向量,其中V是词汇量;隐含层是N维向量h;输出层是被onehot编码过的目标词y。输入向量通过 VN 维的权重矩阵W连接到隐含层;隐含层通过 NV 维的权重矩阵 W’ 连接到输出层。
fastText模型架构和word2vec的CBOW模型架构非常相似。下面是fastText模型架构图:
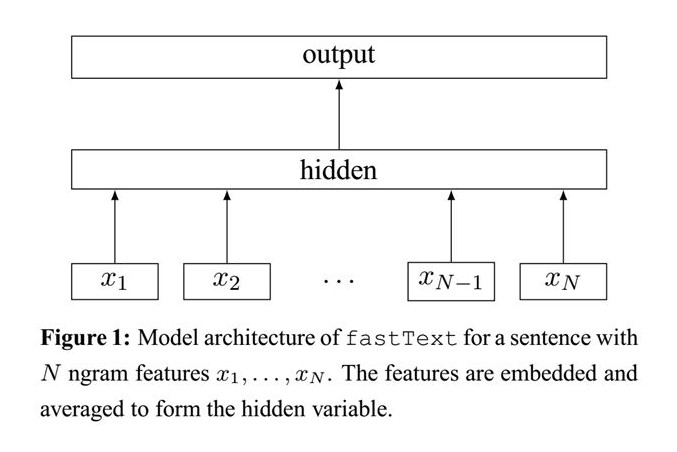
注意:此架构图没有展示词向量的训练过程。可以看到,和CBOW一样,fastText模型也只有三层:输入层、隐含层、输出层(Hierarchical Softmax),输入都是多个经向量表示的单词,输出都是一个特定 的target,隐含层都是对多个词向量的叠加平均。不同的是,CBOW的输入是目标单词的上下文,fastText的输入是多个单词及其n-gram特征,这些特征用来表示单个文档;CBOW的输入单词被onehot编码过, fastText的输入特征是被embedding过;CBOW的输出是目标词汇,fastText的输出是文档对应的类标。
值得注意的是,fastText在输入时,将单词的字符级别的n-gram向量作为额外的特征;在输出时,fastText采用了分层Softmax,大大降低了模型训练时间。
3、实践
地址:https://github.com/zgd716/FastText
-data 存放数据
-vocabs 存放字典文件
-runs 存放模型及tensorboard文件
-data_helper.py 处理数据
-config.py 配置文件
-fast_text.py FastText类
-train.py 训练模型
-predict.py 预测

