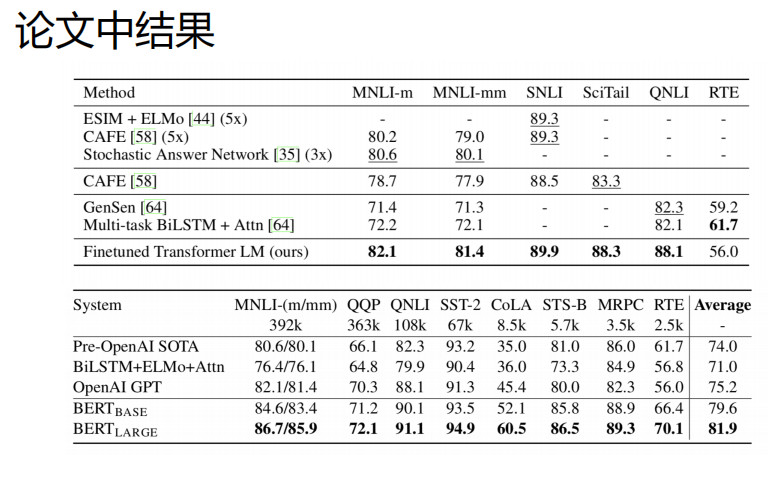
bert
BERT(Bidirectional Encoder Representations from Transformers)近期提出之后,作为一个Word2Vec的替代者,其在NLP领域的11个方向大幅刷新了精度,可以说是近年来自残差网络最优突破性的一项技术了。论文的主要特点以下几点:
使用了Transformer作为算法的主要框架,Transformer能更彻底的捕捉语句中的双向关系;
使用了Mask Language Model(MLM)和 Next Sentence Prediction(NSP) 的多任务训练目标;
使用更强大的机器训练更大规模的数据,使BERT的结果达到了全新的高度,并且Google开源了BERT模型,用户可以直接使用BERT作为Word2Vec的转换矩阵并高效的将其应用到自己的任务中。
BERT的本质上是通过在海量的语料的基础上运行自监督学习方法为单词学习一个好的特征表示,所谓自监督学习是指在没有人工标注的数据上运行的监督学习。在以后特定的NLP任务中,我们可以直接使用BERT的特征表示作为该任务的词嵌入特征。所以BERT提供的是一个供其它任务迁移学习的模型,该模型可以根据任务微调或者固定之后作为特征提取器。BERT的源码和模型10月31号已经在Github上开源,简体中文和多语言模型也于11月3号开源。。)
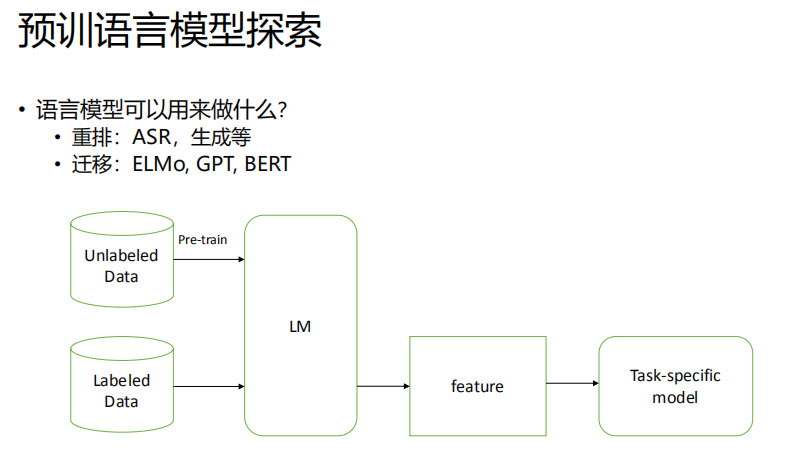
语言模型简介
文本表征
文本表征是的 “数字形式 ”表达:
模型的运算需要数字
模型的运算是连续的
对于𝑥, 𝑦 ∈ (0, 1),我们总可以找到介于x与y之间的值;
自然语言是离散的
对于𝑣 ∈ {开心, 很开心, 非常开心},我们无法定义任意两个词之间的词;
文本表征
one-hot, tf-idf…
word2vec, doc2vec, glove, fastext…
ELMo, GPT, BERT
词向量
分布式假设
相同上下文语境的词有相似的含义
词向量的弊端
每个词一个固定表征
结合上下文的动态表征
ELMo, GPT, BERT等基于语言模型的表征

语言模型
语言模型是什么
语言模型本质上是概率模型
在给定前文的基础上,从概率上预测接下来的内容
它的目标就是学会语言的“套路”
随着前文越详细,预测的目标越明确
传统语言模型的问题


N元语言模型
过于短程的依赖
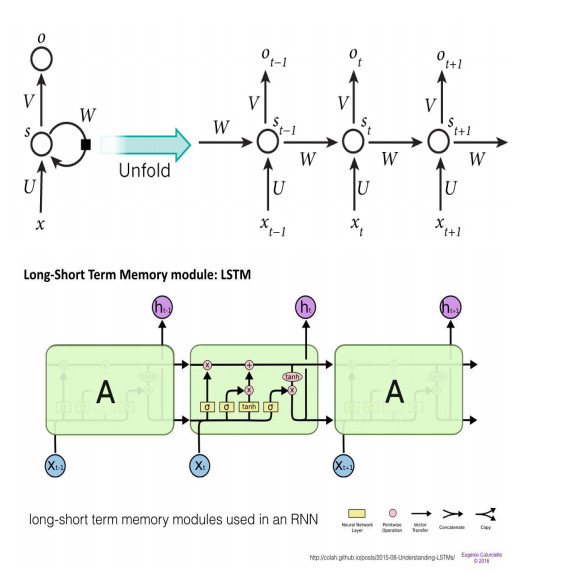
解决长程依赖的途径
RNN+LSTM,GRU
Attention
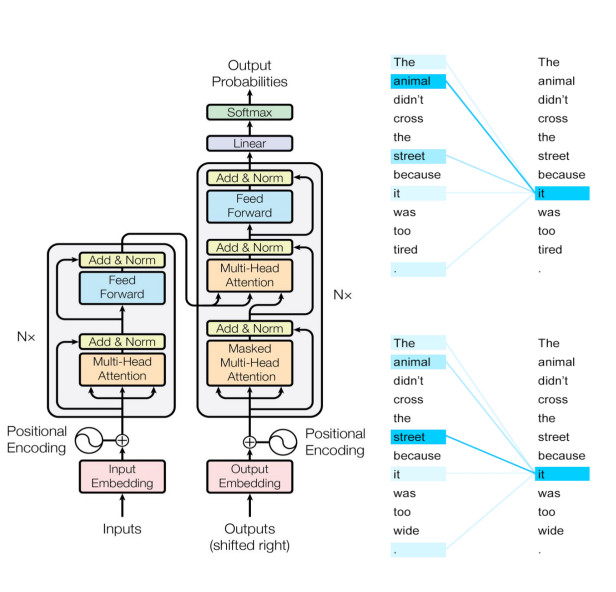
深度学习与语言模型
神经网络语言模型
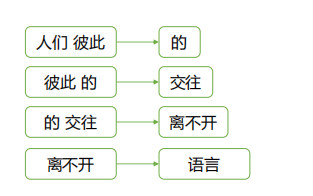
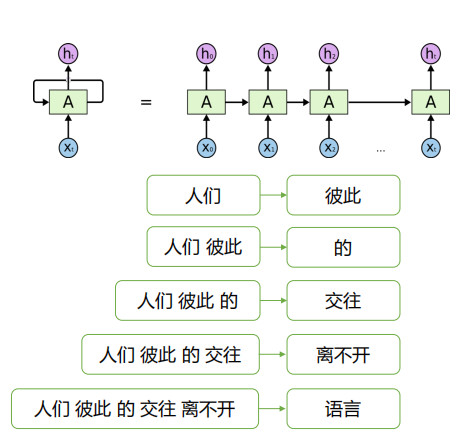
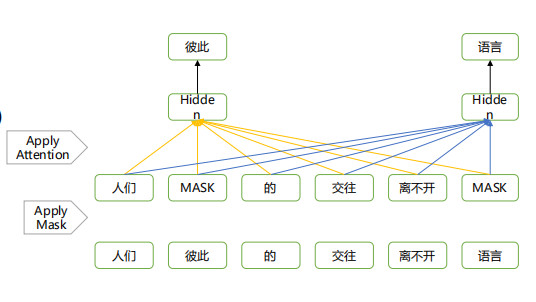
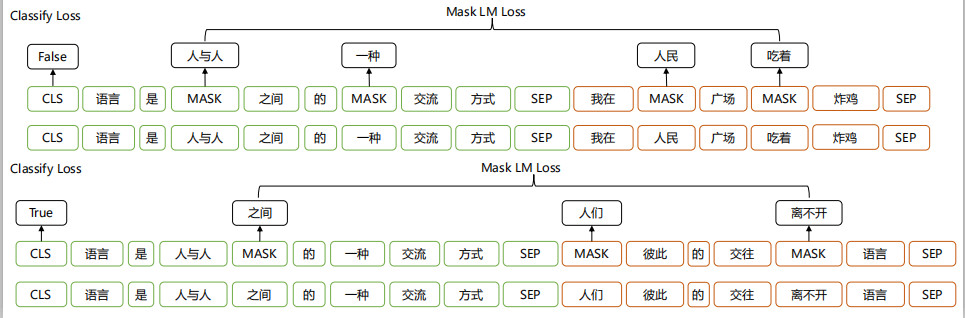
如:人们彼此的交往离不开语言
单向RNN:
双向RNN:
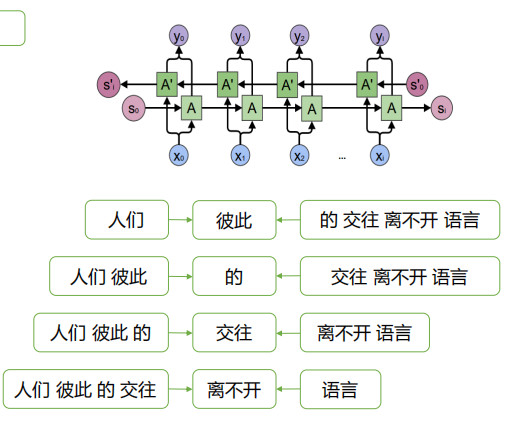
单向Attention:
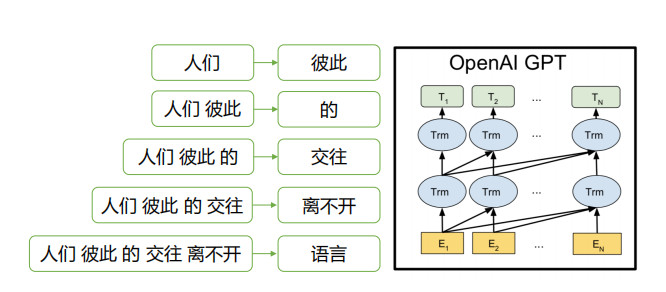
双向编码与网络深度的冲突
加深网络的层数可以带来更好的效果
深度的增加导致标签信息泄露
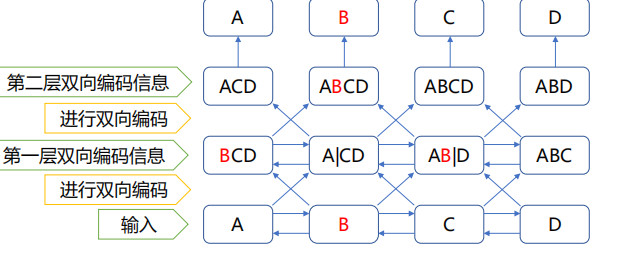
解决方式
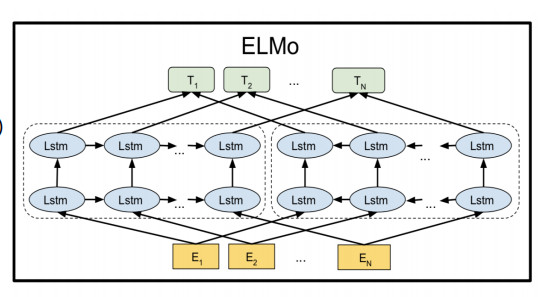
多层单向Rnn,独立建模(ELMo)
Mask LM (BERT)
深度学习的模型可以从文本中学到什么?
根据不同的语料以及任务,深度学习模型可以从数据中学到不同的内容:
通用文本:句法结构、pos、词共现,层级关系等。
(Blevins et al., ACL 2018; Zhang & Bowman, 2018)
(Peters et al., NAACL 2018; EMNLP 2018)
诗句:格律、节奏
(Lau et al., ACL 2018)
结构化文本:格式、规则
(Yin and Neubig, ACL 2017)
BERT解析
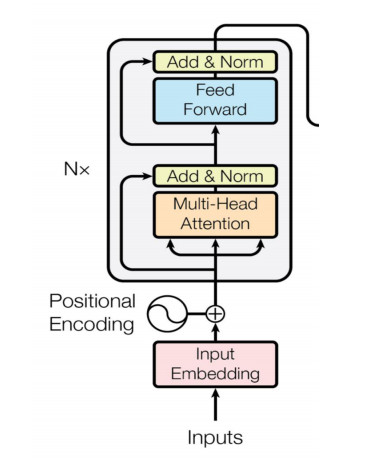
bert的基本结构
Embedding
Word embedding
Position embedding
Type embedding
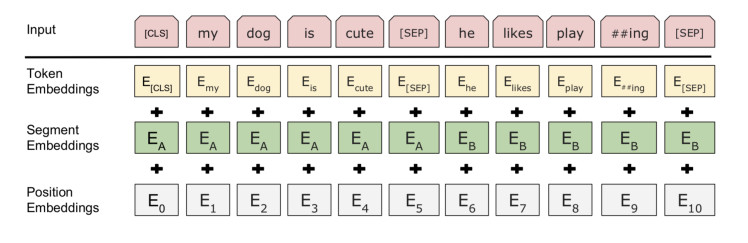
Transformer Encoder
Multi-Head Attention
Feed Forward
Losses
Mask LM
Next sentence prediction
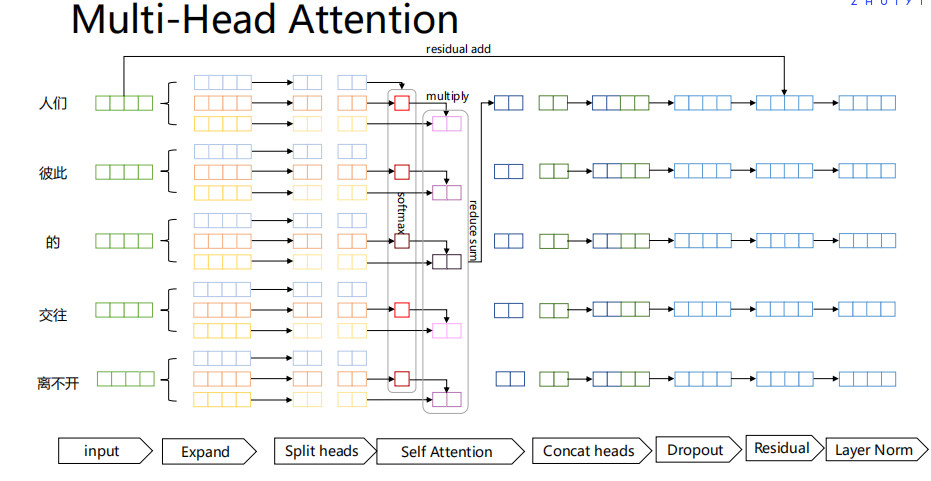
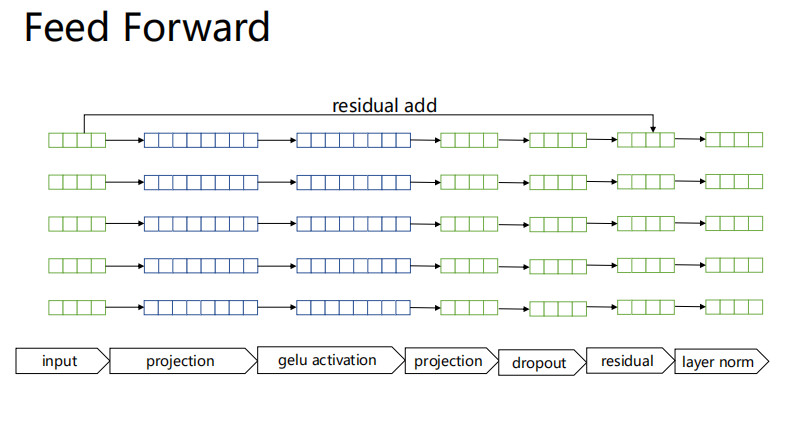
模型模块详解
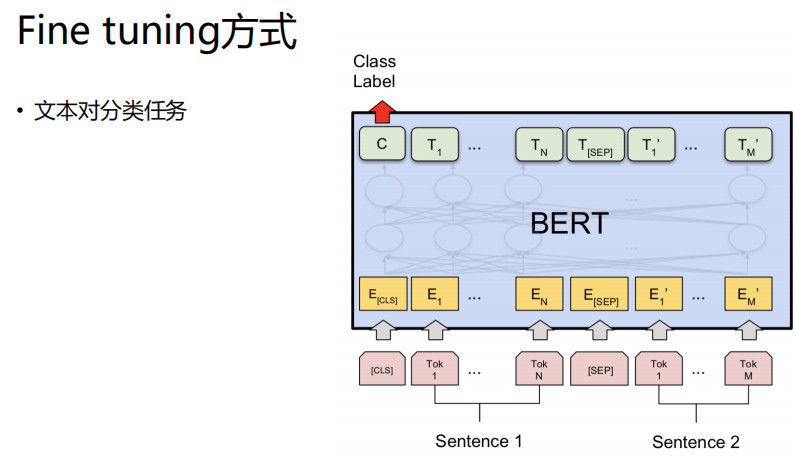
文本分类任务
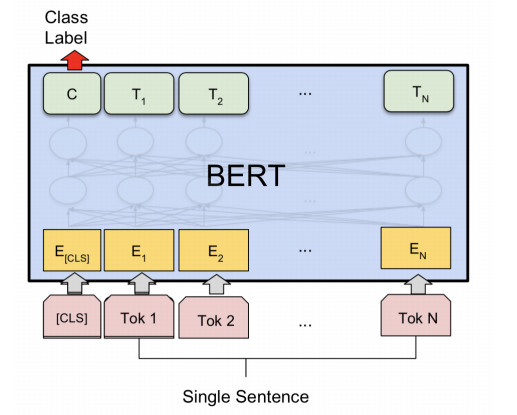
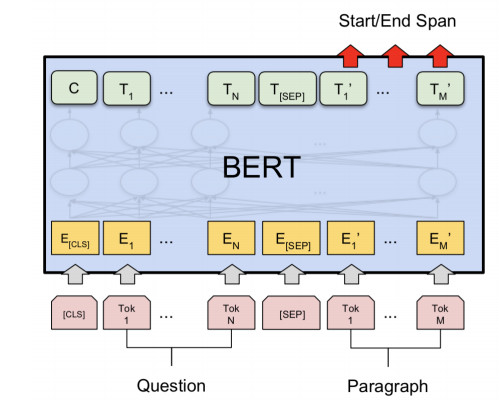
QA任务
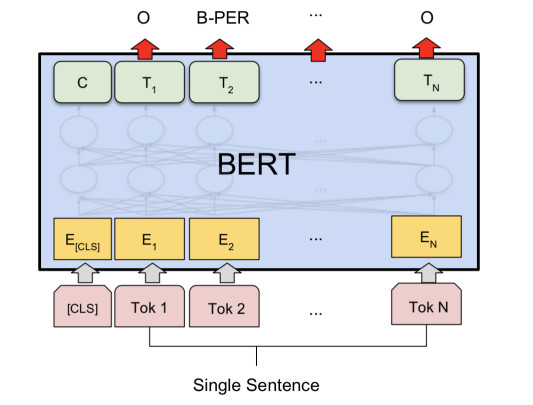
文本Tagging任务
一些细节
预训练数据的构建
输入的两个部分都是包含完整句子
同一句中不会同时Mask同一个词
非连续的句子都是取自不同文档
有一定的概率让输入的有效文本长度小于输入全长(利用padding补齐)
对于超过全长的文本,随机从第一部分部分和第二部分部分的头和尾削减
模型
Encoder LM任务的输出后经过一个gelu非线性层再进行LM Loss的计算;
Classify任务的输出后经过一个tanh非线性层再进行的二分类
应用
如何使用预训练模型
实验心得